Theorem 2.20: A language is generated by some context-free grammar if and only if it is recognized by some push-down automaton.
Definition: a language is called context-free if it is the language generated by a context-free grammar. The class of all context-free language over a given alphabet \(\Sigma\) is called CFL.
Consequences:
Quick proof that every regular language is context free
To prove closure of the class of context-free languages under a given operation, we can choose either of two modes of proof (via CFGs or PDAs) depending on which is easier
Over \(\Sigma = \{a,b\}\), let \(L = \{ a^n b^m \mid n \neq m \}\). Goal: Prove \(L\) is context-free.
Suppose \(L_1\) and \(L_2\) are context-free languages over \(\Sigma\). Goal: \(L_1 \cup L_2\) is also context-free.
Approach 1: with PDAs
Let \(M_1 = ( Q_1, \Sigma, \Gamma_1, \delta_1, q_1, F_1)\) and \(M_2 = ( Q_2, \Sigma, \Gamma_2, \delta_2, q_2, F_2)\) be PDAs with \(L(M_1) = L_1\) and \(L(M_2) = L_2\).
Define \(M =\)
Approach 2: with CFGs
Let \(G_1 = (V_1, \Sigma, R_1, S_1)\) and \(G_2 = (V_2, \Sigma, R_2, S_2)\) be CFGs with \(L(G_1) = L_1\) and \(L(G_2) = L_2\).
Define \(G =\)
Suppose \(L_1\) and \(L_2\) are context-free languages over \(\Sigma\). Goal: \(L_1 \circ L_2\) is also context-free.
Approach 1: with PDAs
Let \(M_1 = ( Q_1, \Sigma, \Gamma_1, \delta_1, q_1, F_1)\) and \(M_2 = ( Q_2, \Sigma, \Gamma_2, \delta_2, q_2, F_2)\) be PDAs with \(L(M_1) = L_1\) and \(L(M_2) = L_2\).
Define \(M =\)
Approach 2: with CFGs
Let \(G_1 = (V_1, \Sigma, R_1, S_1)\) and \(G_2 = (V_2, \Sigma, R_2, S_2)\) be CFGs with \(L(G_1) = L_1\) and \(L(G_2) = L_2\).
Define \(G =\)
Summary
Over a fixed alphabet \(\Sigma\), a language \(L\) is regular
iff it is described by some regular expression
iff it is recognized by some DFA
iff it is recognized by some NFA
Over a fixed alphabet \(\Sigma\), a language \(L\) is context-free
iff it is generated by some CFG
iff it is recognized by some PDA
Fact: Every regular language is a context-free language.
Fact: There are context-free languages that are not nonregular.
Fact: There are countably many regular languages.
Fact: There are countably inifnitely many context-free languages.
Consequence: Most languages are not context-free!
Examples of non-context-free languages
\[\begin{aligned} &\{ a^n b^n c^n \mid 0 \leq n , n \in \mathbb{Z}\}\\ &\{ a^i b^j c^k \mid 0 \leq i \leq j \leq k , i \in \mathbb{Z}, j \in \mathbb{Z}, k \in \mathbb{Z}\}\\ &\{ ww \mid w \in \{0,1\}^* \} \end{aligned}\] (Sipser Ex 2.36, Ex 2.37, 2.38)
There is a Pumping Lemma for CFL that can be used to prove a specific language is non-context-free: If \(A\) is a context-free language, there there is a number \(p\) where, if \(s\) is any string in \(A\) of length at least \(p\), then \(s\) may be divided into five pieces \(s = uvxyz\) where (1) for each \(i \geq 0\), \(uv^ixy^iz \in A\), (2) \(|uv|>0\), (3) \(|vxy| \leq p\). We will not go into the details of the proof or application of Pumping Lemma for CFLs this quarter.
A set \(X\) is said to be closed under an operation \(OP\) if, for any elements in \(X\), applying \(OP\) to them gives an element in \(X\).
| True/False | Closure claim |
|---|---|
| True | The set of integers is closed under multiplication. |
| \(\forall x \forall y \left( ~(x \in \mathbb{Z} \wedge y \in \mathbb{Z})\to xy \in \mathbb{Z}~\right)\) | |
| True | For each set \(A\), the power set of \(A\) is closed under intersection. |
| \(\forall A_1 \forall A_2 \left( ~(A_1 \in \mathcal{P}(A) \wedge A_2 \in \mathcal{P}(A) \in \mathbb{Z}) \to A_1 \cap A_2 \in \mathcal{P}(A)~\right)\) | |
| The class of regular languages over \(\Sigma\) is closed under complementation. | |
| The class of regular languages over \(\Sigma\) is closed under union. | |
| The class of regular languages over \(\Sigma\) is closed under intersection. | |
| The class of regular languages over \(\Sigma\) is closed under concatenation. | |
| The class of regular languages over \(\Sigma\) is closed under Kleene star. | |
| The class of context-free languages over \(\Sigma\) is closed under complementation. | |
| The class of context-free languages over \(\Sigma\) is closed under union. | |
| The class of context-free languages over \(\Sigma\) is closed under intersection. | |
| The class of context-free languages over \(\Sigma\) is closed under concatenation. | |
| The class of context-free languages over \(\Sigma\) is closed under Kleene star. | |
Assume \(\Sigma = \{0,1, \#\}\)
| \(\Sigma^*\) | Regular / nonregular and context-free / not context-free |
| \(\{0^i\# 1^j \mid i \geq 0, j \geq 0\}\) | Regular / nonregular and context-free / not context-free |
| \(\{0^i1^j\# 1^j0^i \mid i \geq 0, j \geq 0\}\) | Regular / nonregular and context-free / not context-free |
| \(\{0^i1^j\# 0^i 1^j \mid i \geq 0, j \geq 0\}\) | Regular / nonregular and context-free / not context-free |
Turing machines: unlimited read + write memory, unlimited time (computation can proceed without “consuming” input and can re-read symbols of input)
Division betweeen program (CPU, state diagram) and data
Unbounded memory gives theoretical limit to what modern computation (including PCs, supercomputers, quantum computers) can achieve
State diagram formulation is simple enough to reason about (and diagonalize against) while expressive enough to capture modern computation
For Turing machine \(M= (Q, \Sigma, \Gamma, \delta, q_0, q_{accept}, q_{reject})\) the computation of \(M\) on a string \(w\) over \(\Sigma\) is:
Read/write head starts at leftmost position on tape.
Input string is written on \(|w|\)-many leftmost cells of tape, rest of the tape cells have the blank symbol. Tape alphabet is \(\Gamma\) with \(\textvisiblespace\in \Gamma\) and \(\Sigma \subseteq \Gamma\). The blank symbol \(\textvisiblespace \notin \Sigma\).
Given current state of machine and current symbol being read at the tape head, the machine transitions to next state, writes a symbol to the current position of the tape head (overwriting existing symbol), and moves the tape head L or R (if possible). Formally, transition function is \[\delta: Q\times \Gamma \to Q \times \Gamma \times \{L, R\}\]
Computation ends if and when machine enters either the accept or the reject state. This is called halting. Note: \(q_{accept} \neq q_{reject}\).
The language recognized by the Turing machine \(M\), is \[\{ w \in \Sigma^* \mid \textrm{computation of $M$ on $w$ halts after entering the accept state}\} = \{ w \in \Sigma^* \mid w \textrm{ is accepted by } M\}\]
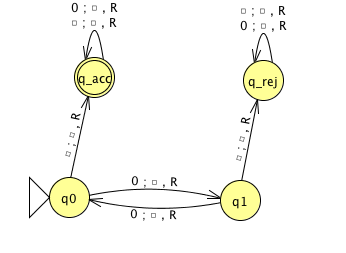
An example Turing machine: \(\Sigma = \phantom{\hspace{1in}}, \Gamma = \phantom{\hspace{1in}}\) \[\delta ( ( q0, 0) ) =\]
Formal definition:
Sample computation:
| \(q0\downarrow\) | ||||||
|---|---|---|---|---|---|---|
| \(0\) | \(0\) | \(0\) | \(\textvisiblespace\) | \(\textvisiblespace\) | \(\textvisiblespace\) | \(\textvisiblespace\) |
The language recognized by this machine is …
Extra practice:
Formal definition:
Sample computation:
Sipser Figure 3.10
Conventions in state diagram of TM: \(b \to R\) label means \(b \to b, R\) and all arrows missing from diagram represent transitions with output \((q_{reject}, \textvisiblespace , R)\)
2
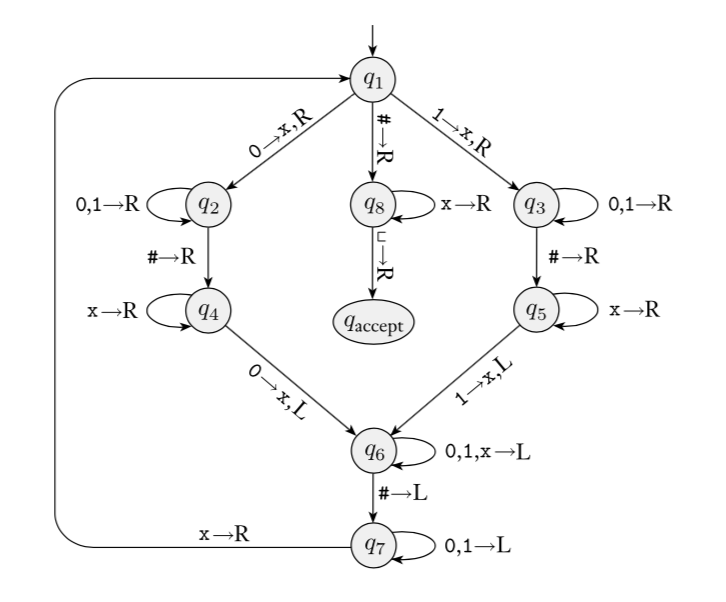
Implementation level description of this machine:
Zig-zag across tape to corresponding positions on either side of \(\#\) to check whether the characters in these positions agree. If they do not, or if there is no \(\#\), reject. If they do, cross them off.
Once all symbols to the left of the \(\#\) are crossed off, check for any un-crossed-off symbols to the right of \(\#\); if there are any, reject; if there aren’t, accept.
Computation on input string \(01\#01\)
| \(q_1 \downarrow\) | ||||||
|---|---|---|---|---|---|---|
| \(0\) | \(1\) | \(\#\) | \(0\) | \(1\) | \(\textvisiblespace\) | \(\textvisiblespace\) |
The language recognized by this machine is \[\{ w \# w \mid w \in \{0,1\}^* \}\]
Extra practice
Computation on input string \(01\#1\)
| \(q_1\downarrow\) | ||||||
|---|---|---|---|---|---|---|
| \(0\) | \(1\) | \(\#\) | \(1\) | \(\textvisiblespace\) | \(\textvisiblespace\) | \(\textvisiblespace\) |
| Language | \(s \in L\) | \(s \notin L\) | Is the language regular or nonregular? |
|---|---|---|---|
| \(\{a^nb^n \mid 0 \leq n \leq 5 \}\) | |||
| \(\{b^n a^n \mid n \geq 2\}\) | |||
| \(\{a^m b^n \mid 0 \leq m\leq n\}\) | |||
| \(\{a^m b^n \mid m \geq n+3, n \geq 0\}\) | |||
| \(\{b^m a^n \mid m \geq 1, n \geq 3\}\) | |||
| \(\{ w \in \{a,b\}^* \mid w = w^\mathcal{R} \}\) | |||
| \(\{ ww^\mathcal{R} \mid w\in \{a,b\}^* \}\) | |||
Regular sets are not the end of the story
Many nice / simple / important sets are not regular
Limitation of the finite-state automaton model: Can’t "count", Can only remember finitely far into the past, Can’t backtrack, Must make decisions in "real-time"
We know actual computers are more powerful than this model...
The next model of computation. Idea: allow some memory of unbounded size. How?
To generalize regular expressions: context-free
grammars
To generalize NFA: Pushdown automata, which is like an NFA with access to a stack: Number of states is fixed, number of entries in stack is unbounded. At each step (1) Transition to new state based on current state, letter read, and top letter of stack, then (2) (Possibly) push or pop a letter to (or from) top of stack. Accept a string iff there is some sequence of states and some sequence of stack contents which helps the PDA processes the entire input string and ends in an accepting state.
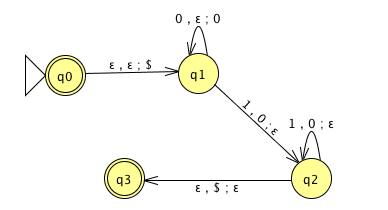
Trace the computation of this PDA on the input string \(01\).
Trace the computation of this PDA on the input string \(011\).
Definition A pushdown automaton (PDA) is specified by a \(6\)-tuple \((Q, \Sigma, \Gamma, \delta, q_0, F)\) where \(Q\) is the finite set of states, \(\Sigma\) is the input alphabet, \(\Gamma\) is the stack alphabet, \[\delta: Q \times \Sigma_\varepsilon \times \Gamma_\varepsilon \to \mathcal{P}( Q \times \Gamma_\varepsilon)\] is the transition function, \(q_0 \in Q\) is the start state, \(F \subseteq Q\) is the set of accept states.
2 Formal definition
Draw the state diagram of a PDA with \(\Sigma = \Gamma\).
Draw the state diagram of a PDA with \(\Sigma \cap \Gamma = \emptyset\).
A PDA recognizing the set \(\{ \hspace{1.5 in} \}\) can be informally described as:
Read symbols from the input. As each 0 is read, push it onto the stack. As soon as 1s are seen, pop a 0 off the stack for each 1 read. If the stack becomes empty and there is exactly one 1 left to read, read that 1 and accept the input. If the stack becomes empty and there are either zero or more than one 1s left to read, or if the 1s are finished while the stack still contains 0s, or if any 0s appear in the input following 1s, reject the input.
State diagram for this PDA:
Consider the state diagram of a PDA with input alphabet \(\Sigma\) and stack alphabet \(\Gamma\).
| Label | means |
|---|---|
| \(a, b ; c\) when \(a \in \Sigma\), \(b\in \Gamma\), \(c \in \Gamma\) | |
| \(a, \varepsilon ; c\) when \(a \in \Sigma\), \(c \in \Gamma\) | |
| \(a, b ; \varepsilon\) when \(a \in \Sigma\), \(b\in \Gamma\) | |
| \(a, \varepsilon ; \varepsilon\) when \(a \in \Sigma\) | |
How does the meaning change if \(a\) is replaced by \(\varepsilon\)?
Note: alternate notation is to replace \(;\) with \(\to\)
For the PDA state diagrams below, \(\Sigma = \{0,1\}\).
| Mathematical description of language | State diagram of PDA recognizing language |
|---|---|
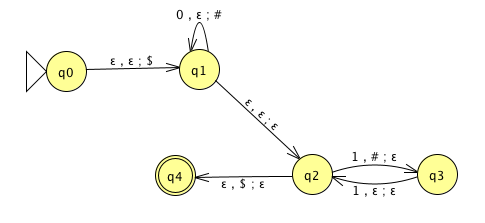 |
|
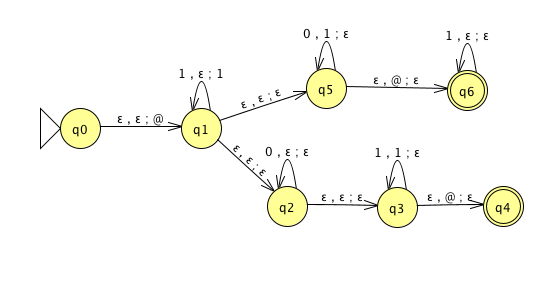 |
|
| \(\{ 0^i 1^j 0^k \mid i,j,k \geq 0 \}\) |
For Turing machine \(M= (Q, \Sigma, \Gamma, \delta, q_0, q_{accept}, q_{reject})\) the computation of \(M\) on a string \(w\) over \(\Sigma\) is:
Read/write head starts at leftmost position on tape.
Input string is written on \(|w|\)-many leftmost cells of tape, rest of the tape cells have the blank symbol. Tape alphabet is \(\Gamma\) with \(\textvisiblespace\in \Gamma\) and \(\Sigma \subseteq \Gamma\). The blank symbol \(\textvisiblespace \notin \Sigma\).
Given current state of machine and current symbol being read at the tape head, the machine transitions to next state, writes a symbol to the current position of the tape head (overwriting existing symbol), and moves the tape head L or R (if possible). Formally, transition function is \[\delta: Q\times \Gamma \to Q \times \Gamma \times \{L, R\}\]
Computation ends if and when machine enters either the accept or the reject state. This is called halting. Note: \(q_{accept} \neq q_{reject}\).
The language recognized by the Turing machine \(M\), is \[\{ w \in \Sigma^* \mid \textrm{computation of $M$ on $w$ halts after entering the accept state}\} = \{ w \in \Sigma^* \mid w \textrm{ is accepted by } M\}\]
To define a Turing machine, we could give a
Formal definition, namely the \(7\)-tuple of parameters including set of states, input alphabet, tape alphabet, transition function, start state, accept state, and reject state; or,
Implementation-level definition: English prose that describes the Turing machine head movements relative to contents of tape, and conditions for accepting / rejecting based on those contents.
Conventions for drawing state diagrams of Turing machines: (1) omit the reject state from the diagram (unless it’s the start state), (2) any missing transitions in the state diagram have value \((q_{reject}, ~\textvisiblespace~ , R)\).
Sipser Figure 3.10
2
Implementation level description of this machine:
Zig-zag across tape to corresponding positions on either side of \(\#\) to check whether the characters in these positions agree. If they do not, or if there is no \(\#\), reject. If they do, cross them off.
Once all symbols to the left of the \(\#\) are crossed off, check for any un-crossed-off symbols to the right of \(\#\); if there are any, reject; if there aren’t, accept.
Computation on input string \(01\#01\)
| \(q_1 \downarrow\) | ||||||
|---|---|---|---|---|---|---|
| \(0\) | \(1\) | \(\#\) | \(0\) | \(1\) | \(\textvisiblespace\) | \(\textvisiblespace\) |
The language recognized by this machine is \[\{ w \# w \mid w \in \{0,1\}^* \}\]
A language \(L\) is recognized by a Turing machine \(M\) means
A Turing machine \(M\) recognizes a language \(L\) if means
A Turing machine \(M\) is a decider means
A language \(L\) is decided by a Turing machine \(M\) means
A Turing machine \(M\) decides a language \(L\) means
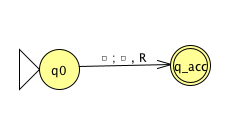
Fix \(\Sigma = \{0,1\}\), \(\Gamma = \{ 0, 1, \textvisiblespace\}\) for the Turing machines with the following state diagrams:
 |
 |
| Implementation level description: | Implementation level description: |
| Example of string accepted: | Example of string accepted: |
| Example of string rejected: | Example of string rejected: |
| Decider? Yes / No | Decider? Yes / No |
 |
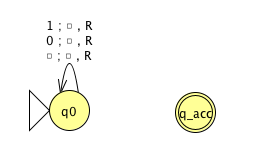 |
| Implementation level description: | Implementation level description: |
| Example of string accepted: | Example of string accepted: |
| Example of string rejected: | Example of string rejected: |
| Decider? Yes / No | Decider? Yes / No |
Two models of computation are called equally expressive when every language recognizable with the first model is recognizable with the second, and vice versa.
True / False: NFAs and PDAs are equally expressive.
True / False: Regular expressions and CFGs are equally expressive.
Some examples of models that are equally expressive with deterministic Turing machines:
The May-stay machine model is the same as the usual Turing machine model, except that on each transition, the tape head may move L, move R, or Stay.
Formally: \((Q, \Sigma, \Gamma, \delta, q_0, q_{accept}, q_{reject})\) where \[\delta: Q \times \Gamma \to Q \times \Gamma \times \{L, R, S\}\]
Claim: Turing machines and May-stay machines are equally expressive. To prove …
To translate a standard TM to a may-stay machine:
To translate one of the may-stay machines to standard TM: any time TM would Stay, move right then left.
Formally: suppose \(M_S = (Q, \Sigma, \Gamma, \delta, q_0, q_{acc}, q_{rej})\) has \(\delta: Q \times \Gamma \to Q \times \Gamma \times \{L, R, S\}\). Define the Turing-machine \[M_{new} = (\phantom{\hspace{2.5in}})\]
A multitape Turing macihne with \(k\) tapes can be formally representated as \((Q, \Sigma, \Gamma, \delta, q_0, q_{acc}, q_{rej})\) where \(Q\) is the finite set of states, \(\Sigma\) is the input alphabet with \(\textvisiblespace \notin \Sigma\), \(\Gamma\) is the tape alphabet with \(\Sigma \subsetneq \Gamma\) , \(\delta: Q\times \Gamma^k\to Q \times \Gamma^k \times \{L,R\}^k\) (where \(k\) is the number of states)
If \(M\) is a standard TM, it is a \(1\)-tape machine.
To translate a \(k\)-tape machine to a standard TM: Use a new symbol to separate the contents of each tape and keep track of location of head with special version of each tape symbol. Sipser Theorem 3.13
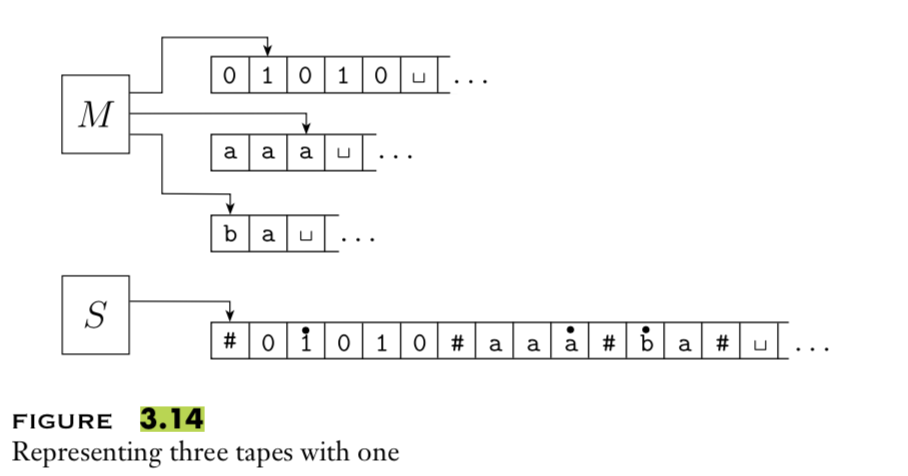
Extra practice: Define a machine \((Q, \Gamma, b, \Sigma, q_0, F, \delta)\) where \(Q\) is the finite set of states \(\Gamma\) is the tape alphabet, \(b \in \Gamma\) is the blank symbol, \(\Sigma \subsetneq \Gamma\) is the input alphabet, \(q_0 \in Q\) is the start state, \(F \subseteq Q\) is the set of accept states, \(\delta: (Q \setminus F) \times \Gamma \not\to Q \times \Gamma \times \{L, R\}\) is a partial transition function If computation enters a state in \(F\), it accepts If computation enters a configuration where \(\delta\) is not defined, it rejects . Hopcroft and Ullman, cited by Wikipedia
Enumerators give a different model of computation where a language is produced, one string at a time, rather than recognized by accepting (or not) individual strings.
Each enumerator machine has finite state control, unlimited work tape, and a printer. The computation proceeds according to transition function; at any point machine may “send” a string to the printer. \[E = (Q, \Sigma, \Gamma, \delta, q_0, q_{print})\] \(Q\) is the finite set of states, \(\Sigma\) is the output alphabet, \(\Gamma\) is the tape alphabet (\(\Sigma \subsetneq\Gamma, \textvisiblespace \in \Gamma \setminus \Sigma\)), \[\delta: Q \times \Gamma \times \Gamma \to Q \times \Gamma \times \Gamma \times \{L, R\} \times \{L, R\}\] where in state \(q\), when the working tape is scanning character \(x\) and the printer tape is scanning character \(y\), \(\delta( (q,x,y) ) = (q', x', y', d_w, d_p)\) means transition to control state \(q'\), write \(x'\) on the working tape, write \(y'\) on the printer tape, move in direction \(d_w\) on the working tape, and move in direction \(d_p\) on the printer tape. The computation starts in \(q_0\) and each time the computation enters \(q_{print}\) the string from the leftmost edge of the printer tape to the first blank cell is considered to be printed.
The language enumerated by \(E\), \(L(E)\), is \(\{ w \in \Sigma^* \mid \text{$E$ eventually, at finite time, prints $w$} \}\).
cc 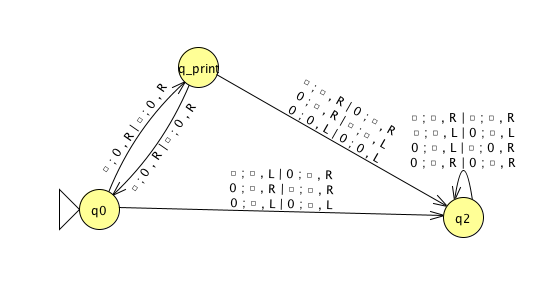 &
&
| \(q0\) | ||||||
|---|---|---|---|---|---|---|
| \(\textvisiblespace ~*\) | \(\textvisiblespace\) | \(\textvisiblespace\) | \(\textvisiblespace\) | \(\textvisiblespace\) | \(\textvisiblespace\) | \(\textvisiblespace\) |
| \(\textvisiblespace ~*\) | \(\textvisiblespace\) | \(\textvisiblespace\) | \(\textvisiblespace\) | \(\textvisiblespace\) | \(\textvisiblespace\) | \(\textvisiblespace\) |
Theorem 3.21 A language is Turing-recognizable iff some enumerator enumerates it. Proof next time …
To define a Turing machine, we could give a
Formal definition: the \(7\)-tuple of parameters including set of states, input alphabet, tape alphabet, transition function, start state, accept state, and reject state; or,
Implementation-level definition: English prose that describes the Turing machine head movements relative to contents of tape, and conditions for accepting / rejecting based on those contents.
High-level description: description of algorithm (precise sequence of instructions), without implementation details of machine. As part of this description, can “call" and run another TM as a subroutine.
Theorem 3.21 A language is Turing-recognizable iff some enumerator enumerates it.
Proof:
Assume \(L\) is enumerated by some enumerator, \(E\), so \(L = L(E)\). We’ll use \(E\) in a subroutine within a high-level description of a new Turing machine that we will build to recognize \(L\).
Goal: build Turing machine \(M_E\) with \(L(M_E) = L(E)\).
Define \(M_E\) as follows: \(M_E =\) “On input \(w\),
Run \(E\). For each string \(x\) printed by \(E\).
Check if \(x = w\). If so, accept (and halt); otherwise, continue."
Assume \(L\) is Turing-recognizable and there is a Turing machine \(M\) with \(L = L(M)\). We’ll use \(M\) in a subroutine within a high-level description of an enumerator that we will build to enumerate \(L\).
Goal: build enumerator \(E_M\) with \(L(E_M) = L(M)\).
Idea: check each string in turn to see if it is in \(L\).
How? Run computation of \(M\) on each string. But: need to be careful about computations that don’t halt.
Recall String order for \(\Sigma = \{0,1\}\): \(s_1 = \varepsilon\), \(s_2 = 0\), \(s_3 = 1\), \(s_4 = 00\), \(s_5 = 01\), \(s_6 = 10\), \(s_7 = 11\), \(s_8 = 000\), …
Define \(E_M\) as follows: \(E_{M} =\) “ ignore any input. Repeat the following for \(i=1, 2, 3, \ldots\)
Run the computations of \(M\) on \(s_1\), \(s_2\), …, \(s_i\) for (at most) \(i\) steps each
For each of these \(i\) computations that accept during the (at most) \(i\) steps, print out the accepted string."
Nondeterministic Turing machine
At any point in the computation, the nondeterministic machine may proceed according to several possibilities: \((Q, \Sigma, \Gamma, \delta, q_0, q_{acc}, q_{rej})\) where \[\delta: Q \times \Gamma \to \mathcal{P}(Q \times \Gamma \times \{L, R\})\] The computation of a nondeterministic Turing machine is a tree with branching when the next step of the computation has multiple possibilities. A nondeterministic Turing machine accepts a string exactly when some branch of the computation tree enters the accept state.
Given a nondeterministic machine, we can use a \(3\)-tape Turing machine to simulate it by doing a breadth-first search of computation tree: one tape is “read-only” input tape, one tape simulates the tape of the nondeterministic computation, and one tape tracks nondeterministic branching. Sipser page 178
Two models of computation are called equally expressive when every language recognizable with the first model is recognizable with the second, and vice versa.
Church-Turing Thesis (Sipser p. 183): The informal notion of algorithm is formalized completely and correctly by the formal definition of a Turing machine. In other words: all reasonably expressive models of computation are equally expressive with the standard Turing machine.
Claim: If two languages (over a fixed alphabet \(\Sigma\)) are Turing-recognizable, then their union is as well.
Proof using Turing machines:
Proof using nondeterministic Turing machines:
Proof using enumerators:
The state diagram of an NFA over \(\{a,b\}\) is below. The formal definition of this NFA is:
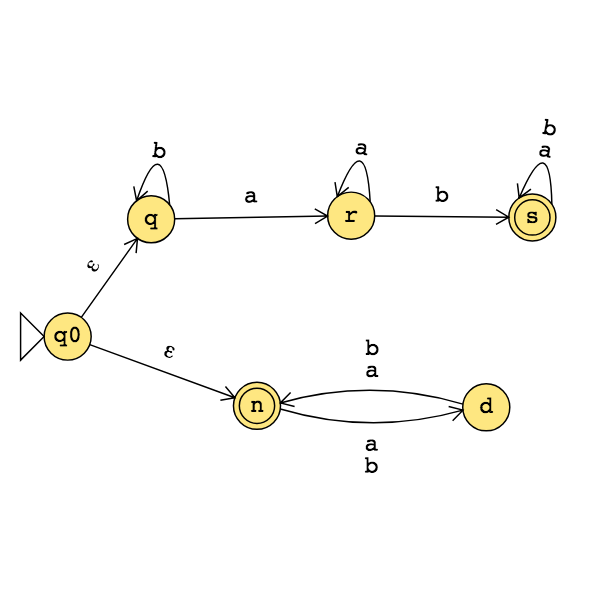
The language recognized by this NFA is:
Suppose \(A_1, A_2\) are languages over an alphabet \(\Sigma\). Claim: if there is a NFA \(N_1\) such that \(L(N_1) = A_1\) and NFA \(N_2\) such that \(L(N_2) = A_2\), then there is another NFA, let’s call it \(N\), such that \(L(N) = A_1 \cup A_2\).
Proof idea: Use nondeterminism to choose which of \(N_1\), \(N_2\) to run.
Formal construction: Let \(N_1 = (Q_1, \Sigma, \delta_1, q_1, F_1)\) and \(N_2 = (Q_2, \Sigma, \delta_2,q_2, F_2)\) and assume \(Q_1 \cap Q_2 = \emptyset\) and that \(q_0 \notin Q_1 \cup Q_2\). Construct \(N = (Q, \Sigma, \delta, q_0, F_1 \cup F_2)\) where
\(Q =\)
\(\delta: Q \times \Sigma_\varepsilon \to \mathcal{P}(Q)\) is defined by, for \(q \in Q\) and \(a \in \Sigma_{\varepsilon}\): \[\phantom{\delta((q,a))=\begin{cases} \delta_1 ((q,a)) &\qquad\text{if } q\in Q_1 \\ \delta_2 ((q,a)) &\qquad\text{if } q\in Q_2 \\ \{q1,q2\} &\qquad\text{if } q = q_0, a = \varepsilon \\ \emptyset\text{if } q= q_0, a \neq \varepsilon \end{cases}}\]
Proof of correctness would prove that \(L(N) = A_1 \cup A_2\) by considering an arbitrary string accepted by \(N\), tracing an accepting computation of \(N\) on it, and using that trace to prove the string is in at least one of \(A_1\), \(A_2\); then, taking an arbitrary string in \(A_1 \cup A_2\) and proving that it is accepted by \(N\). Details left for extra practice.
Over the alphabet \(\{a,b\}\), the language \(L\) described by the regular expression \(\Sigma^* a \Sigma^* b\)
includes the strings and excludes the strings
The state diagram of a NFA recognizing \(L\) is:
Suppose \(A_1, A_2\) are languages over an alphabet \(\Sigma\). Claim: if there is a NFA \(N_1\) such that \(L(N_1) = A_1\) and NFA \(N_2\) such that \(L(N_2) = A_2\), then there is another NFA, let’s call it \(N\), such that \(L(N) = A_1 \circ A_2\).
Proof idea: Allow computation to move between \(N_1\) and \(N_2\) “spontaneously" when reach an accepting state of \(N_1\), guessing that we’ve reached the point where the two parts of the string in the set-wise concatenation are glued together.
Formal construction: Let \(N_1 = (Q_1, \Sigma, \delta_1, q_1, F_1)\) and \(N_2 = (Q_2, \Sigma, \delta_2,q_2, F_2)\) and assume \(Q_1 \cap Q_2 = \emptyset\). Construct \(N = (Q, \Sigma, \delta, q_0, F)\) where
\(Q =\)
\(q_0 =\)
\(F =\)
\(\delta: Q \times \Sigma_\varepsilon \to \mathcal{P}(Q)\) is defined by, for \(q \in Q\) and \(a \in \Sigma_{\varepsilon}\): \[\delta((q,a))=\begin{cases} \delta_1 ((q,a)) &\qquad\text{if } q\in Q_1 \textrm{ and } q \notin F_1\\ \delta_1 ((q,a)) &\qquad\text{if } q\in F_1 \textrm{ and } a \in \Sigma\\ \delta_1 ((q,a)) \cup \{q_2\} &\qquad\text{if } q\in F_1 \textrm{ and } a = \varepsilon\\ \delta_2 ((q,a)) &\qquad\text{if } q\in Q_2 \end{cases}\]
Proof of correctness would prove that \(L(N) = A_1 \circ A_2\) by considering an arbitrary string accepted by \(N\), tracing an accepting computation of \(N\) on it, and using that trace to prove the string can be written as the result of concatenating two strings, the first in \(A_1\) and the second in \(A_2\); then, taking an arbitrary string in \(A_1 \circ A_2\) and proving that it is accepted by \(N\). Details left for extra practice.
Suppose \(A\) is a language over an alphabet \(\Sigma\). Claim: if there is a NFA \(N\) such that \(L(N) = A\), then there is another NFA, let’s call it \(N'\), such that \(L(N') = A^*\).
Proof idea: Add a fresh start state, which is an accept state. Add spontaneous moves from each (old) accept state to the old start state.
Formal construction: Let \(N = (Q, \Sigma, \delta, q_1, F)\) and assume \(q_0 \notin Q\). Construct \(N' = (Q', \Sigma, \delta', q_0, F')\) where
\(Q' = Q \cup \{q_0\}\)
\(F' = F \cup \{q_0\}\)
\(\delta': Q' \times \Sigma_\varepsilon \to \mathcal{P}(Q')\) is defined by, for \(q \in Q'\) and \(a \in \Sigma_{\varepsilon}\): \[\delta'((q,a))=\begin{cases} \delta ((q,a)) &\qquad\text{if } q\in Q \textrm{ and } q \notin F\\ \delta ((q,a)) &\qquad\text{if } q\in F \textrm{ and } a \in \Sigma\\ \delta ((q,a)) \cup \{q_1\} &\qquad\text{if } q\in F \textrm{ and } a = \varepsilon\\ \{q_1\} &\qquad\text{if } q = q_0 \textrm{ and } a = \varepsilon \\ \emptyset &\qquad\text{if } q = q_0 \textrm { and } a \in \Sigma \end{cases}\]
Proof of correctness would prove that \(L(N') = A^*\) by considering an arbitrary string accepted by \(N'\), tracing an accepting computation of \(N'\) on it, and using that trace to prove the string can be written as the result of concatenating some number of strings, each of which is in \(A\); then, taking an arbitrary string in \(A^*\) and proving that it is accepted by \(N'\). Details left for extra practice.
Application: A state diagram for a NFA over \(\Sigma = \{a,b\}\) that recognizes \(L (( \Sigma^* b)^* )\):
True or False: The state diagram of any DFA is also the state diagram of a NFA.
True or False: The state diagram of any NFA is also the state diagram of a DFA.
True or False: The formal definition \((Q, \Sigma, \delta, q_0, F)\) of any DFA is also the formal definition of a NFA.
True or False: The formal definition \((Q, \Sigma, \delta, q_0, F)\) of any NFA is also the formal definition of a DFA.
Consider the state diagram of an NFA over \(\{a,b\}\):
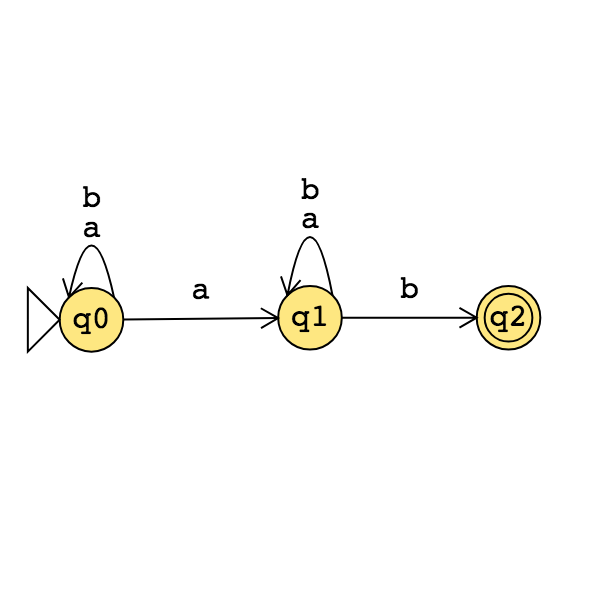
The language recognized by this NFA is
The state diagram of a DFA recognizing this same language is:
Suppose \(A\) is a language over an alphabet \(\Sigma\). Claim: if there is a NFA \(N\) such that \(L(N) = A\) then there is a DFA \(M\) such that \(L(M) = A\).
Proof idea: States in \(M\) are “macro-states" – collections of states from \(N\) – that represent the set of possible states a computation of \(N\) might be in.
Formal construction: Let \(N = (Q, \Sigma, \delta, q_0, F)\). Define \[M = (~ \mathcal{P}(Q), \Sigma, \delta', q', \{ X \subseteq Q \mid X \cap F \neq \emptyset \}~ )\] where \(q' = \{ q \in Q \mid \text{$q = q_0$ or is accessible from $q_0$ by spontaneous moves in $N$} \}\) and \[\delta' (~(X, x)~) = \{ q \in Q \mid q \in \delta( ~(r,x)~) ~\text{for some $r \in X$ or is accessible from such an $r$ by spontaneous moves in $N$} \}\]
Consider the state diagram of an NFA over \(\{0,1\}\). Use the “macro-state” construction to find an equivalent DFA.
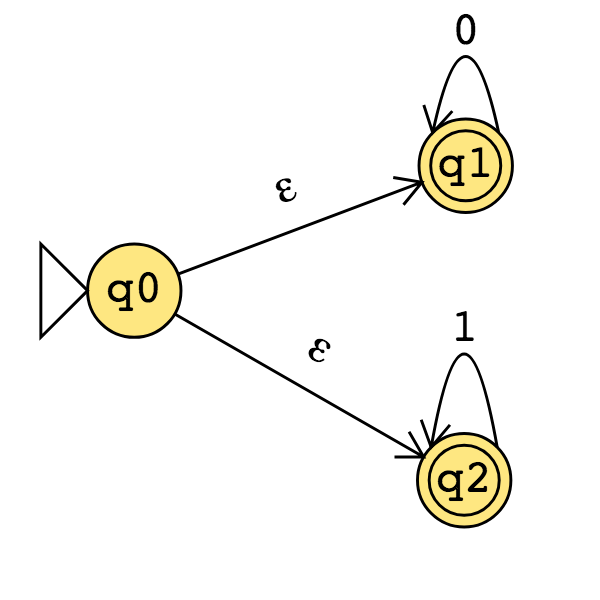
Prune this diagram to get an equivalent DFA with only the “macro-states" reachable from the start state.
Suppose \(A\) is a language over an alphabet \(\Sigma\). Claim: if there is a regular expression \(R\) such that \(L(R) = A\), then there is a NFA, let’s call it \(N\), such that \(L(N) = A\).
Structural induction: Regular expression is built from basis regular expressions using inductive steps (union, concatenation, Kleene star symbols). Use constructions to mirror these in NFAs.
Application: A state diagram for a NFA over \(\{a,b\}\) that recognizes \(L(a^* (ab)^*)\):
Suppose \(A\) is a language over an alphabet \(\Sigma\). Claim: if there is a DFA \(M\) such that \(L(M) = A\), then there is a regular expression, let’s call it \(R\), such that \(L(R) = A\).
Proof idea: Trace all possible paths from start state to accept state. Express labels of these paths as regular expressions, and union them all.
Add new start state with \(\varepsilon\) arrow to old start state.
Add new accept state with \(\varepsilon\) arrow from old accept states. Make old accept states non-accept.
Remove one (of the old) states at a time: modify regular expressions on arrows that went through removed state to restore language recognized by machine.
Application: Find a regular expression describing the language recognized by the DFA with state diagram
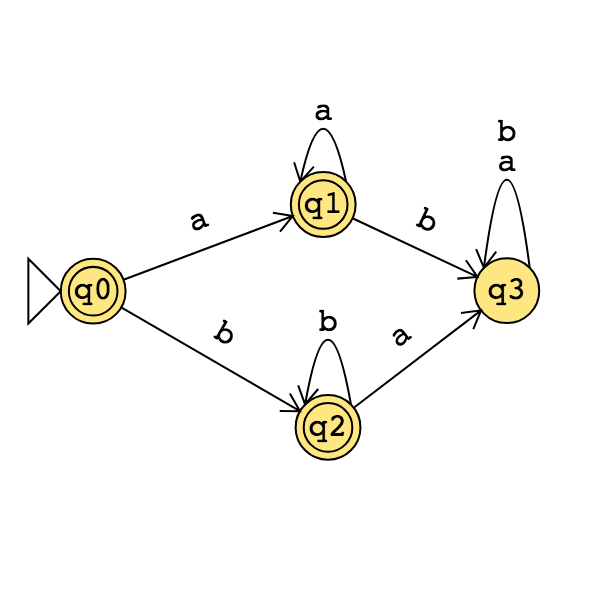
Conclusion: For each language \(L\),
There is a DFA that recognizes \(L\) \(\exists M
~(M \textrm{ is a DFA and } L(M) = A)\)
if and only if
There is a NFA that recognizes \(L\) \(\exists N
~(N \textrm{ is a NFA and } L(N) = A)\)
if and only if
There is a regular expression that describes \(L\) \(\exists R
~(R \textrm{ is a regular expression and } L(R) =
A)\)
A language is called regular when any (hence all) of the above three conditions are met.
Review: Formal definition of DFA: \(M = (Q, \Sigma, \delta, q_0, F)\)
2
Finite set of states \(Q\)
Alphabet \(\Sigma\)
Transition function \(\delta\)
Start state \(q_0\)
Accept (final) states \(F\)
In the state diagram of \(M\), how many outgoing arrows are there from each state?
\(M = ( \{ q, r, s\}, \{a,b\}, \delta, q, \{s\} )\) where \(\delta\) is (rows labelled by states and columns labelled by symbols):
| \(\delta\) | \(a\) | \(b\) |
|---|---|---|
| \(q\) | \(r\) | \(q\) |
| \(r\) | \(r\) | \(s\) |
| \(s\) | \(s\) | \(s\) |
The state diagram for \(M\) is
Give two examples of strings that are accepted by \(M\) and two examples of strings that are rejected by \(M\):
Add “labels" for states in the state diagram, e.g. “have not seen any of desired pattern yet” or “sink state”.
We can use the analysis of the roles of the states in the state diagram to describe the language recognized by the DFA.
\(L(M) =\)
A regular expression describing \(L(M)\) is
Let the alphabet be \(\Sigma_1 = \{0,1\}\).
A state diagram for a DFA that recognizes \(\{w \mid w~\text{contains at most two $1$'s} \}\) is
A state diagram for a DFA that recognizes \(\{w \mid w~\text{contains more than two $1$'s} \}\) is
Extra example: A state diagram for DFA recognizing \[\{w \mid w~\text{is a string over $\{0,1\}$ whose length is not a multiple of $3$} \}\]
Let \(n\) be an arbitrary positive integer. What is a formal definition for a DFA recognizing \[\{w \mid w~\text{is a string over $\{0,1\}$ whose length is not a multiple of $n$} \}?\]
Suppose A is a language over an alphabet \(\Sigma\). By definition, this means A is a subset of \(\Sigma^*\). Claim: if there is a DFA \(M\) such that \(L(M) = A\) then there is another DFA, let’s call it \(M'\), such that \(L(M') = \overline{A}\), the complement of \(A\), defined as \(\{ w \in \Sigma^* \mid w \notin A \}\).
Proof idea:
Proof:
A useful (optional) bit of terminology: the iterated transition function of a DFA \(M = (Q, \Sigma, \delta, q_0, F)\) is defined recursively by \[\delta^* (~(q,w)~) =\begin{cases} q \qquad &\text{if $q \in Q, w = \varepsilon$} \\ \delta( ~(q,a)~) \qquad &\text{if $q \in Q$, $w = a \in \Sigma$ } \\ \delta(~(\delta^*(q,u), a) ~) \qquad &\text{if $q \in Q$, $w = ua$ where $u \in \Sigma^*$ and $a \in \Sigma$} \end{cases}\]
Using this terminology, \(M\) accepts a string \(w\) over \(\Sigma\) if and only if \(\delta^*( ~(q_0,w)~) \in F\).
Fix \(\Sigma = \{a,b\}\). A state diagram for a DFA that recognizes \(\{w \mid w~\text{has $ab$ as a substring and is of even length} \}\):
Suppose \(A_1, A_2\) are languages over an alphabet \(\Sigma\). Claim: if there is a DFA \(M_1\) such that \(L(M_1) = A_1\) and DFA \(M_2\) such that \(L(M_2) = A_2\), then there is another DFA, let’s call it \(M\), such that \(L(M) = A_1 \cap A_2\).
Proof idea:
Formal construction:
Application: When \(A_1 = \{w \mid w~\text{has $ab$ as a substring} \}\) and \(A_2 = \{ w \mid w~\text{is of even length} \}\).
Suppose \(A_1, A_2\) are languages over an alphabet \(\Sigma\). Claim: if there is a DFA \(M_1\) such that \(L(M_1) = A_1\) and DFA \(M_2\) such that \(L(M_2) = A_2\), then there is another DFA, let’s call it \(M\), such that \(L(M) = A_1 \cup A_2\). Sipser Theorem 1.25, page 45
Proof idea:
Formal construction:
Application: A state diagram for a DFA that recognizes \(\{w \mid w~\text{has $ab$ as a substring or is of even length} \}\):
| Nondeterministic finite automaton \(M = (Q, \Sigma, \delta, q_0, F)\) | |
| Finite set of states \(Q\) | Can be labelled by any collection of distinct names. Default: \(q0, q1, \ldots\) |
| Alphabet \(\Sigma\) | Each input to the automaton is a string over \(\Sigma\). |
| Arrow labels \(\Sigma_\varepsilon\) | \(\Sigma_\varepsilon = \Sigma \cup \{ \varepsilon\}\). |
| Arrows in the state diagram are labelled either by symbols from \(\Sigma\) or by \(\varepsilon\) | |
| Transition function \(\delta\) | \(\delta: Q \times \Sigma_{\varepsilon} \to \mathcal{P}(Q)\) gives the set of possible next states for a transition |
| from the current state upon reading a symbol or spontaneously moving. | |
| Start state \(q_0\) | Element of \(Q\). Each computation of the machine starts at the start state. |
| Accept (final) states \(F\) | \(F \subseteq Q\). |
| \(M\) accepts the input string | if and only if there is a computation of \(M\) on the input string |
| that processes the whole string and ends in an accept state. | |
| Page 53 | |
The formal definition of the NFA over \(\{0,1\}\) given by this state diagram is:
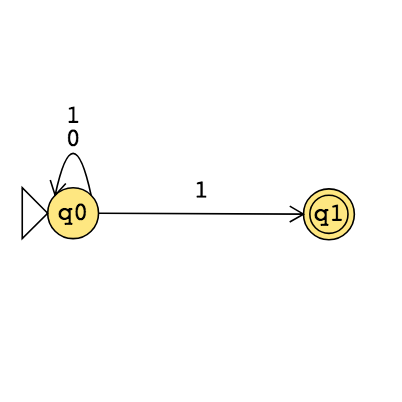
The language over \(\{0,1\}\) recognized by this NFA is:
Change the transition function to get a different NFA which accepts the empty string.
The state diagram of an NFA over \(\{a,b\}\) is below. The formal definition of this NFA is:
The language recognized by this NFA is:
Review: Determine whether each statement below about regular expressions over the alphabet \(\{a,b,c\}\) is true or false:
True or False: \(a \in L(~(a \cup b )~\cup c)\)
True or False: \(ab \in L(~ (a \cup b)^* ~)\)
True or False: \(ba \in L( ~ a^* b^* ~)\)
True or False: \(\varepsilon \in L(a \cup b \cup c)\)
True or False: \(\varepsilon \in L(~ (a \cup b)^* ~)\)
True or False: \(\varepsilon \in L( ~ a^* b^* ~)\)
From the pre-class reading, pages 34-36: A deterministic finite automaton (DFA) is specified by \(M = (Q, \Sigma, \delta, q_0, F)\). This \(5\)-tuple is called the formal definition of the DFA. The DFA can also be represented by its state diagram: with nodes for the state, labelled edges specifying the transition function, and decorations on nodes denoting the start and accept states.
Finite set of states \(Q\) can be labelled by any collection of distinct names. Often we use default state labels \(q0, q1, \ldots\)
The alphabet \(\Sigma\) determines the possible inputs to the automaton. Each input to the automaton is a string over \(\Sigma\), and the automaton “processes” the input one symbol (or character) at a time.
The transition function \(\delta\) gives the next state of the DFA based on the current state of the machine and on the next input symbol.
The start state \(q_0\) is an element of \(Q\). Each computation of the machine starts at the start state.
The accept (final) states \(F\) form a subset of the states of the DFA, \(F \subseteq Q\). These states are used to flag if the machine accepts or rejects an input string.
The computation of a machine on an input string is a sequence of states in the machine, starting with the start state, determined by transitions of the machine as it reads successive input symbols.
The DFA \(M\) accepts the given input string exactly when the computation of \(M\) on the input string ends in an accept state. \(M\) rejects the given input string exactly when the computation of \(M\) on the input string ends in a nonaccept state, that is, a state that is not in \(F\).
The language of \(M\), \(L(M)\), is defined as the set of all strings that are each accepted by the machine \(M\). Each string that is rejected by \(M\) is not in \(L(M)\). The language of \(M\) is also called the language recognized by \(M\).
What is finite about all deterministic finite automata? (Select all that apply)
The size of the machine (number of states, number of arrows)
The number of strings that are accepted by the machine
The length of each computation of the machine
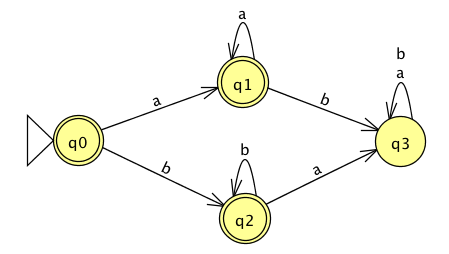
The formal definition of this DFA is
Classify each string \(a, aa, ab, ba, bb, \varepsilon\) as accepted by the DFA or rejected by the DFA.
Why are these the only two options?
The language recognized by this DFA is
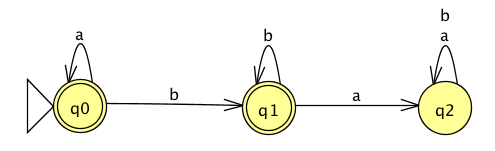
The language recognized by this DFA is
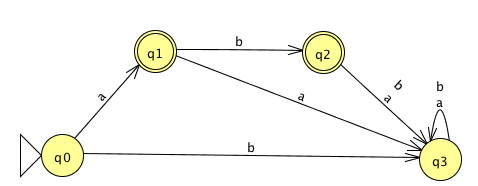
The language recognized by this DFA is